Why AI Agents Hallucinate?

The first time I saw an AI agent hallucinate in a real workflow it wasn’t funny at all.
We had wired it into a product planning flow. The agent sounded confident, referenced internal tools, and even mentioned a “deprecated API” that never existed. On a quick skim, the output looked totally reasonable. Only when someone on the team tried to follow the plan did we realize the agent had calmly invented a whole internal system out of thin air.
There was no crash, no stack trace, nothing that screamed “this is broken”
Just a perfectly formatted, completely wrong answer.
Thats the scary thing about AI hallucinations they don’t show up like bugs. They show up like confident colleagues who are wrong in very convincing ways.
AI agents don’t hallucinate because they’re unstable or “glitchy”
They hallucinate because of how the underlying models are built. Large Language Models (LLMs) are not truth engines. They don’t verify facts. They don’t run a “correctness check” before responding. They optimize for plausibility.
At their core, they estimate the conditional probability of the next token:
P(wₙ | w₁, …, wₙ₋₁)…
Given what’s already been written, they pick the most likely next piece of text. Not the truest one. The most likely one.
When the context is clean and the question is simple, this works beautifully.
When the context is messy or underspecified, the model doesn’t stop and say, “Im missing information” It just keeps predicting.
That fluent, confident guess is what we call an AI hallucination.
If you’ve spent time building with LLM-based agents especially in actual products, not just playground demos you’ve definitely seen this in the wild.
What AI hallucinations feel like in real workflows
Let me explain what AI hallucinations actually look like in real engineering workflows:
- A planning agent invents non-existent services or APIs in your architecture.
- A coding agent writes integration code against an endpoint that doesn’t exist.
- A documentation agent “summarizes” behavior that your product never supported.
- A decision-making agent confidently picks an option based on facts it quietly made up.
The pattern is always the same: the output looks structured, well-written and reasonable so it sails through casual review. No one notices the mistake until something downstream breaks often much later.
The problem is not just that the agent is wrong. The problem is that it doesn’t know it’s wrong and it sounds like it does.
This is why AI hallucinations are so dangerous in domains like product planning, engineering, legal reviews, analytics, and healthcare. The cost isn’t “one wrong answer.” The cost is wrong assumptions getting baked into plans, designs, and code that look correct until they collide with reality.
Why AI Agents Hallucinate by Design
Hallucinations aren’t random bugs, they’re baked into how LLMs work. At their core, these models are massive pattern-matching machines predicting the next token based on statistical likelihood, not truth. There’s no “lie detector” asking “Is this fact real?” or “Can I verify this?” or “What sounds most plausible next?” Throw in messy context like half-baked notes, vague specs and overloaded prompts and the model guesses wildly, connecting dots that don’t exist and confidently inventing APIs or features your system never had.
Worse modern LLMs are fine-tuned for fluency over honesty. They’re rewarded for polished, decisive answers, not “I dont know” so uncertainty gets masked as overconfidence. When faced with gaps in data they extrapolate beyond what they actually know, blending real facts with plausible fiction. Give them fuzzy inputs, and you get confidently wrong outputs perfect for chat demos, disastrous for production AI agents.
AI hallucinations start when models guess instead of know. Clean structure stops the guessing.
Why prompting alone doesn’t fix hallucinations
Most of us started with the same playbook just write better prompts like
“Be accurate” or “Dont make things up” or “If you dont know say I dont know” and “Ask clarifying questions before answering”.
These instructions help a little but they don’t change the fundamental behavior. At the end of the day the model is still predicting the next token based on patterns, not running a truth-checking algorithm.
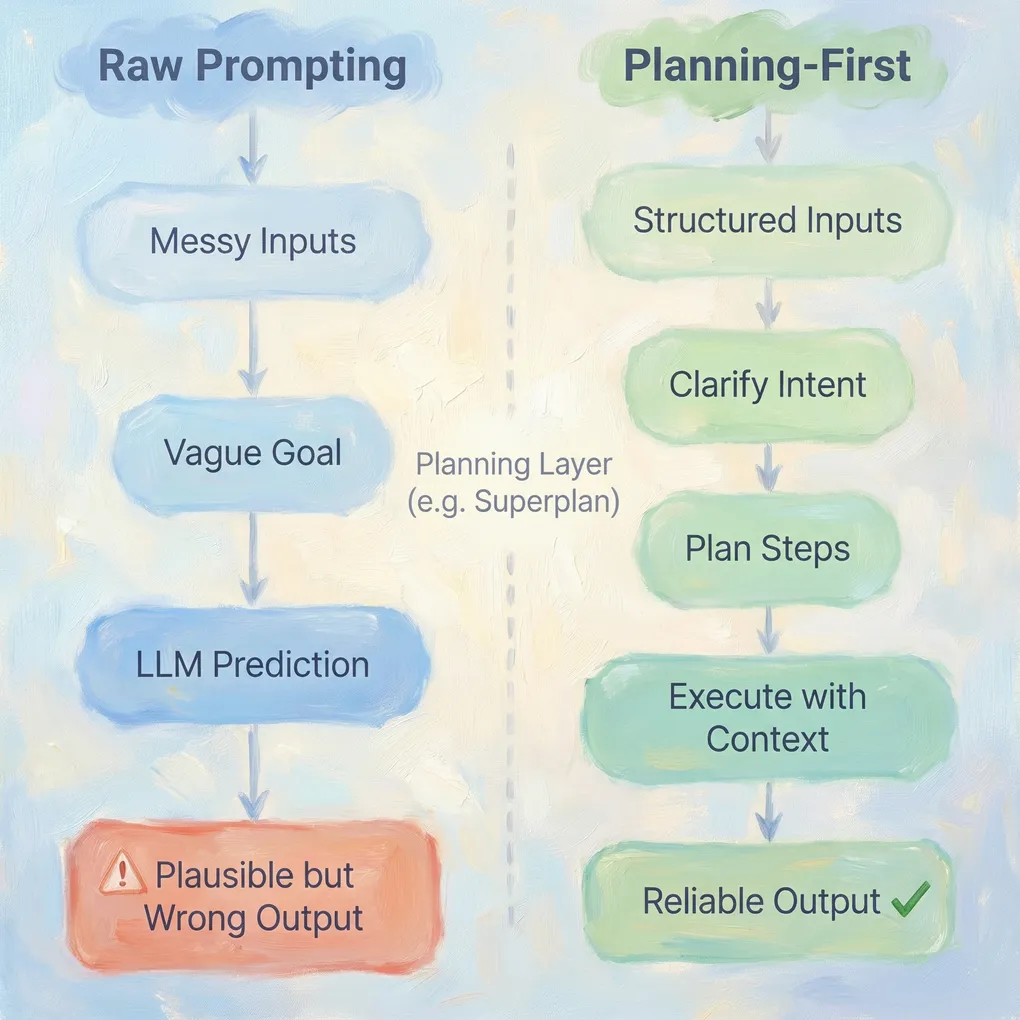
The deeper issue is architectural we ask the same model in the same pass to understand the goal, discover constraints, plan the approach, execute steps and validate results all inside one big, fuzzy, probabilistic blob. There’s no clear boundary between “reasoning” and “doing” When an agent has to figure out what to do while it’s already doing it, it improvises. And in LLM-land, improvisation is another word for hallucination. This is why raw prompting works great for chat-like experiences and small tools, but breaks down when building serious AI agents for real workflows.
If you treat the AI like a junior engineer the solution becomes obvious.
You wouldn’t give a new hire a vague Slack paragraph and let them push to production
you’d turn the idea into a clear spec, define boundaries and constraints, review the plan, then implement.
AI agents need the same thing - a planning layer between “prompt” and “execution”.
Planning-first systems reduce hallucinations by forcing the agent to clarify intent before touching
any real system, break work into explicit inspectable steps,
lock relevant context early instead of guessing later and expose reasoning for human review.
The moment you separate plan from execute, hallucinations become visible a bad plan stands out, vague assumptions get spotted, fake API calls look suspicious on paper in ways they wouldn’t in a single combined response.
How Superplan reduces hallucinations in agents
This is where Superplan comes in it acts as the planning brain in front of your AI agents and Instead of throwing messy notes, docs, and context directly at an LLM and hoping prompting will keep it honest, Superplan forces structure before the agent runs.
Superplan solves these problems by turning the chaos of raw prompting into structured, reliable AI workflows that actually work in production. Instead of typing long prompts and praying, you’re transforming unstructured notes, requirements, tickets, and specs into structured plans with clear objectives, explicit tasks and sub-tasks, linked context for each step, and defined constraints/non-goals. This eliminates guesswork from the start.
One sneaky hallucination source is “context sprawl” when agents drown in too much information and start free-associating instead of focusing. Superplan fixes this with explicit context boundaries agents only see relevant data for the current step, irrelevant docs stay out of the decision path, and every action ties to specific inputs. That alone kills countless silent failure modes.
Most hallucinations happen when agents jump straight to action writing code before design clarity, calling APIs on unchecked assumptions or modifying configs from half-understood requirements. Superplan enforces planning as a first-class step agents must outline what they’re going to do and why before execution.
Planning limits improvisation. Improvisation causes hallucinations.
These human-readable plans let you catch issues early like Does this make sense? Are constraints missing? Is the agent assuming fakery? Share them with your team, treat them like AI workflow specs, and stop hallucinations before they become broken scripts or bad decisions. Instead of finding failures at pipeline end, you spot them at the start.
AI hallucinations wont vanish they’re baked into generative models but they’re manageable with Superplan. Treat agents like junior engineers clean scoped inputs, forced planning before execution, human review, and structured tools over bigger prompts. This is how you build production-ready AI that doesn’t lie to you.
Tools like Superplan exist because raw prompting doesn’t scale. Structure does. If you want reliable AI agents, stop relying on clever prompts and start relying on clear, inspectable plans.