Prompting vs Planning: Which Strategy Improves AI Agent Reliability?
If you’ve spent enough time building AI agents, you’ve probably hit this realization: most of the “reliability work” isn’t about the model itself. It’s about the workflow you’ve wrapped around it. Force explicit planning before execution, and you’ll see fewer hallucinations and less drift.
Prompting and planning both help, but in completely different ways. Prompting shapes how the agent responds and what it prioritizes in a single run. Planning shapes what the agent is allowed to do and what it has to commit to before touching any tools, code, or downstream systems. If you actually care about reliability (not just output that looks good), these two aren’t interchangeable.
Prompting is a UI, planning is a system
Prompting is great for improving the quality of individual responses. You throw in guardrails like “ask clarifying questions”, “cite sources”, “don’t make things up” or the classic “think step-by-step” and it works. The output looks more careful.
But here’s the thing, prompting doesn’t fix the core problem. LLMs generate tokens based on what’s plausible, not what’s true, so even with a perfect prompt you’re still asking a probabilistic system to act like a verifier. Sometimes it nails it. Sometimes it fails quietly, and you don’t notice until you’ve already shipped something broken.
Planning takes a different approach. Instead of polishing responses, it stops the agent from making up intent as it goes.
Most agent setups accidentally fall into this pattern: throw a goal at the agent, attach a massive context blob, let it call tools, and hope the narration equals actual reasoning. That’s execution-first thinking. Great for demos, terrible for production.
Planning-first flips everything. You make intent explicit upfront, lock down constraints and non-goals, scope the context properly, decide on steps before running anything, and then execute. A planning layer sits between your raw ideas and actual execution.
Why prompting plateaus in production
Prompting starts breaking down when workflows become multi-step and long-running.
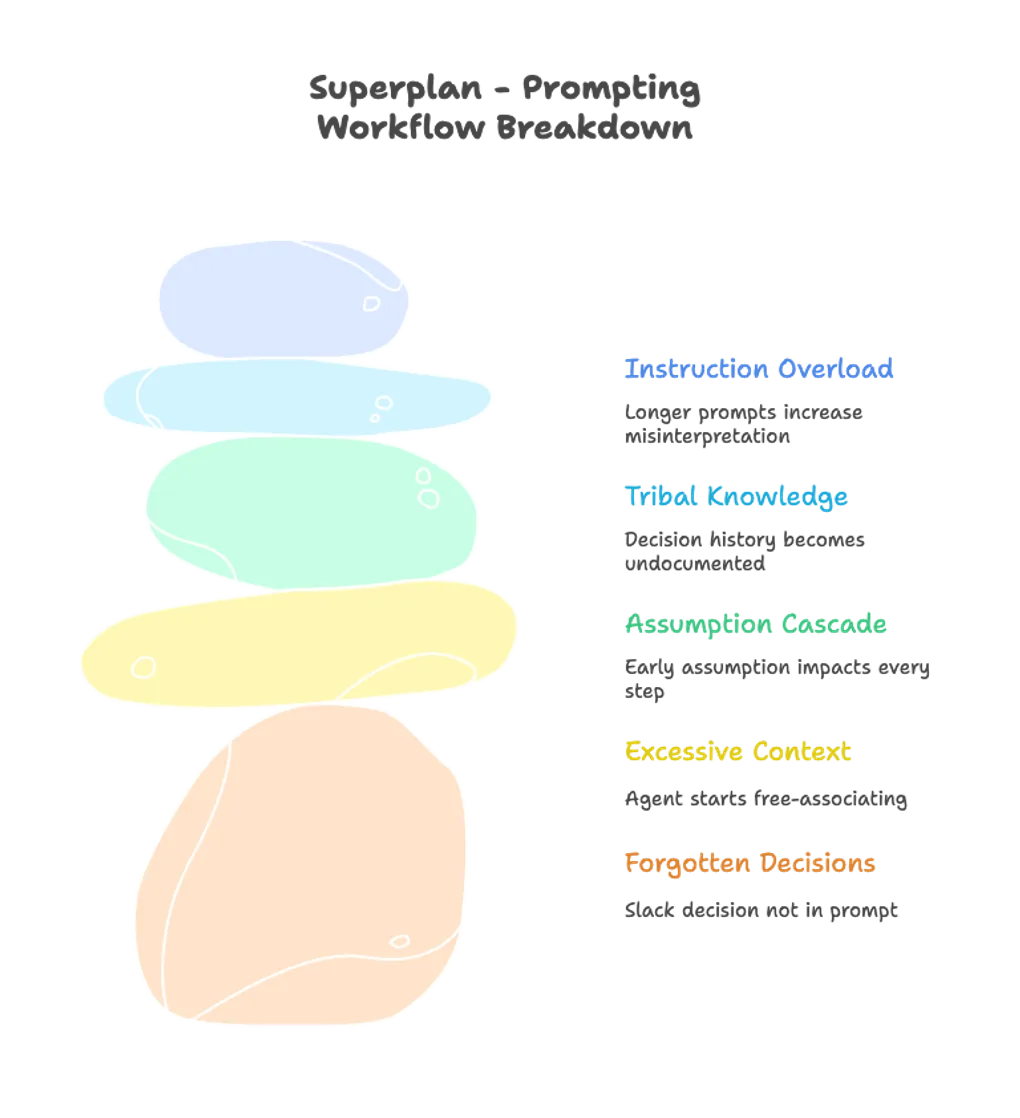
The failure modes look like engineering problems, not language problems. Someone decided X in Slack but it never made it into the prompt, so the agent optimizes for Y. The agent sees too much context and starts free-associating. A small assumption early on becomes the foundation for every subsequent step. Teams iterate by re-prompting, so decision history turns into tribal knowledge.
Adding more instructions doesn’t fix any of this. In fact, longer prompts just create more room for interpretation.
Here’s the uncomfortable truth: a prompt is not a plan. A prompt is a request. And if your agents touch real systems like GitHub, Jira, Linear, databases, infra, or customer data, requests aren’t enough. You need something closer to a spec.
Prompting optimizes a response. Planning constrains an execution.
Planning: the reliability lever teams ignore
Planning works because it creates a durable artifact that outlives any single model run. Think of agent plans like pull requests. They’re inspectable before execution, reviewable by humans, versionable over time, and diffable when behavior changes.
This “plan as artifact” approach makes reliability actually measurable. The plan becomes the contract. Execution becomes an implementation detail.
This is also how you tackle the two most expensive agent failures: Drift, where the agent gradually shifts interpretation as context evolves, and Hallucinations, where the agent fills gaps with confident fiction because it predicts plausibility instead of verifying truth.
Planning won’t eliminate model limitations. But it makes them way less dangerous by reducing how often the model has to guess.
If an agent can’t state the plan in a way a teammate would approve in code review, it shouldn’t be allowed to execute.
The bottom line
If your current workflow is “prompt → run → fix → re-run,” you’re paying tokens to rediscover the same intent over and over. A planning layer shifts that cost upfront into a stable plan, making subsequent execution cheaper in attention, review, and rework. You don’t need a smarter model. You need a system that forces structure before execution begins.
Who this is for
This matters if your AI agents run multi-step tasks instead of single-shot answers, if tool calls have real consequences like writes, merges, deployments, tickets, or customer comms, if your team needs repeatability not just creativity, and if “looks correct” isn’t good enough because it has to actually be correct.
If you’re doing casual prompting or one-off content generation, planning will feel like overkill. But for agentic workflows in production, it’s the missing layer that makes reliability a property of the system, not just a hope you place on the model.

